Billion Scale Similarity Search With GPUs (2017)
January 1, 2024The paper Billion-scale-similarity search with GPUs presents an approximate nearest-neighbor search method that uses GPUs and combines the IVFADC indexing structure with Batcher’s bitonic sorting network. The authors have implemented this method in a library called faiss.
This search method aims to find the \(k\) nearest neighbors of a query vector \(x \in R^d\) among a set of database vectors \([y_i]_{i=0:l}\), based on the L2 distance. Instead of providing an exact result, it returns a suboptimal solution.
$$ L=\text{k-}\argmin\_{i=0:l}||x-y\_i||\_2 $$The IVFADC indexing structure consists of two levels of quantization.
$$ y\approx q(y) = q\_1(y) + q\_2(y-q\_1(y)) $$The first-level quantizer \(q_1\): \(\mathbb{R}^d\rightarrow \mathcal{C}_1\subset \mathbb{R}^d\) maps each vector \(y\) to a coarse centroid \(c \in \mathcal{C_1}\), while the second-level quantizer: \(\mathbb{R}^d\rightarrow \mathcal{C}_2\subset \mathbb{R}^d\) encodes the residual vector after the first level. The database vectors are filtered based on their coarse-level centroids, and the search is then performed on the resulting subset using the second-level quantizer.
$$ L\_{\text{IVF}}=\tau-\argmin\_{c\in\mathcal{C}\_1}||x-c||\_2 $$\(\tau\) is the number of coarse-level centroids, and typically \(|C_1|\approx \sqrt{l}\) trained via \(k\)-means. For the second level, it computes the distances for the database vectors in \(L_{\text{IVF}}\).
$$ L\_{\text{IVFADC}}=k-\argmin\_{i=0:l\ \text{s.t.}\ q\_1(y\_i)\in L\_{\text{IVF}}}||x-q(y\_i)||\_2 $$The second-level quantization \(q_2\) is done using a product quantizer, which divides the vector \(y\) into \(b\) sub-vectors \((y=[y^0\dots y^{b-1}])\) and quantizes each sub-vector independently. \(b\) is an even divisor of the dimension \(d\). The sub-quantizers typically have 256 reproduction values, and the quantization value of the product quantizer is then \(q_2(y)=q^0(y^0)+256\times q^1(y^1)+\dots + 256^{b-1}\times q^{b-1}(y^{b-1})\).
The search uses Batcher’s bitonic sorting network to determine the exact distances in the set of reproduction values. The figure below, cited from the paper, displays the sorting network.
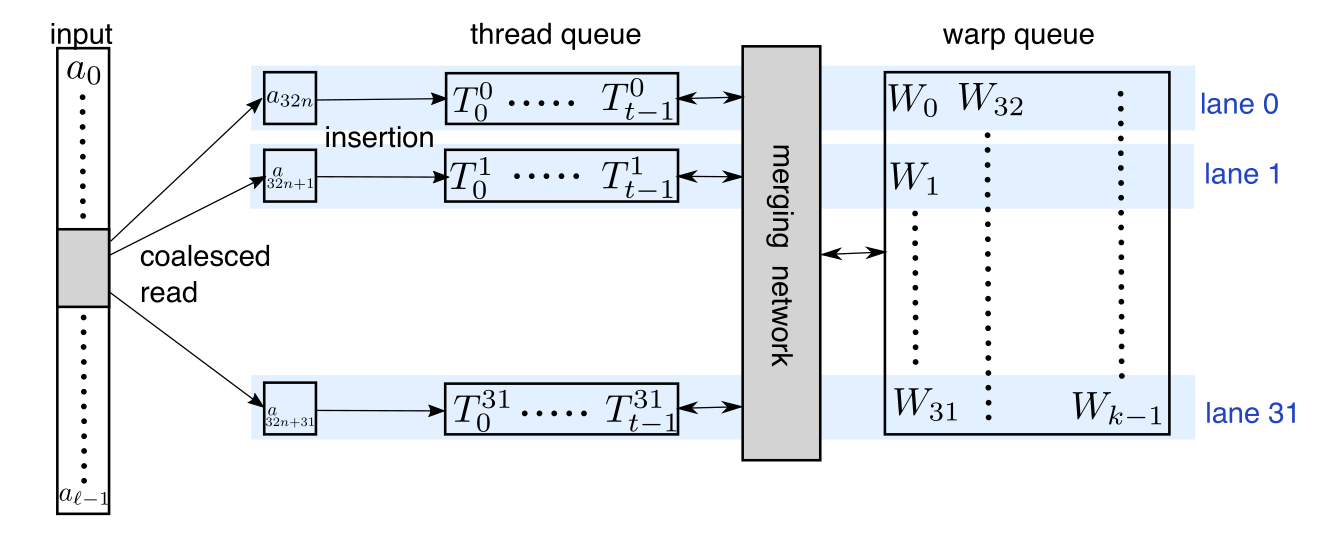 \([a_i]_{i=0:l}\) is provided for selection and \([T^j_i]_{i=0:t}\) represents a priority queue where the elements are ordered from largest to smallest (\(T^j_{i}\ge T^j_{i+1}\)).
\([a_i]_{i=0:l}\) are the sequence provided fro selection, and \([T^j_i]_{i=0:t}\) is a priority queue where the elements are ordered from largest to smallest (\(T^j_{i}\ge T^j_{i+1}\)).
\([W_i]_{i=0:k}\) is the array of \(k\) smallest seen elements.
If a new candidate vector \(a\) is greater than the largest key currently in the queue \(T^j_0\), it is guaranteed that it won’t be included in the final set of \(k\) smallest results.
\([a_i]_{i=0:l}\) is provided for selection and \([T^j_i]_{i=0:t}\) represents a priority queue where the elements are ordered from largest to smallest (\(T^j_{i}\ge T^j_{i+1}\)).
\([a_i]_{i=0:l}\) are the sequence provided fro selection, and \([T^j_i]_{i=0:t}\) is a priority queue where the elements are ordered from largest to smallest (\(T^j_{i}\ge T^j_{i+1}\)).
\([W_i]_{i=0:k}\) is the array of \(k\) smallest seen elements.
If a new candidate vector \(a\) is greater than the largest key currently in the queue \(T^j_0\), it is guaranteed that it won’t be included in the final set of \(k\) smallest results.