Coverage is Not Strongly Correlated with Test Suite Effectiveness (2014)
March 3, 2025There are debates concerning the ability of code coverage to measure the effectiveness of test suites. For instance, Winters et al. argued that setting an objective coverage threshold does not necessarily lead developers to write meaningful tests, as discussed in ‘A Note on Code Coverage’ (Section 11.2.4) in Software Engineering at Google. They also claimed that coverage percentage does not guarantee fault detection ability.
compared with the abundance of rational arguments and anecdotal experiences, empirical studies on this topic are relatively rare. Coverage Is Not Strongly Correlated With Test Suite Effectiveness (ICSE 2014) is an empirical study that was awarded the most influential paper ICSE N-10 at ICSE 2024. The paper investigated correlation between test suite size, coverage and effectiveness. The authors applied mutation testing to Apache POI, Closure, HSQLDB, JFreeChart, and Joda Time. They found a moderate to high correlation between the effectiveness and coverage of a test suite when ignoring the influence of the number of test cases. However, the correlation dropped when suite size was controlled for.
They selected reasonably large projects with at least 100,000 lines of code and approximately 1,000 test cases to enhance the study’s novelty and generalizability. They also required the projects to use Ant as a build system and JUnit as a test harness to facilitate automated data collection. Apache POI is an API for Microsoft Documents, Closure is a Javascript optimizer, HSQLDB is an RDBMS written in Java, JFreeChart is a Java chart library, and Joda Time is a date and time library for Java prior to Java SE 8.
They generated test suites of fixed size by randomly selecting methods annotated with @Test, ensuring no method was selected more than once.
@Test is the Junit annotation that marks annotated method as a test case.
They created test suites with fixed sizes, ranging from 3 to 3,000 methods.
They generated at most 1,000 test suites for each size.
They used C0, C1, and MCC coverage metrics. C0, or statement coverage, measures the fraction of executable statements executed by the test suite. C1, or decision coverage, measures the fraction of branches executed by the test suite. MCC (modified condition coverage) is the most difficult to achieve and is not commonly used in practice.
The study performed mutation testing using PIT, a mutation testing framework. In mutation testing, faults are seeded into the program before a test suite runs. A program with seeded faults is called a mutant. The quality of the test suite was gauged by the number of mutants or faults it detected.
Effectiveness was measured in two ways: raw effectiveness and normalized effectiveness. The raw value is the number of mutants a test suite detected divided by the total number of mutants generated for the program under test. The normalized effectiveness is the number of mutants detected divided by the number of mutants the test suite covers.
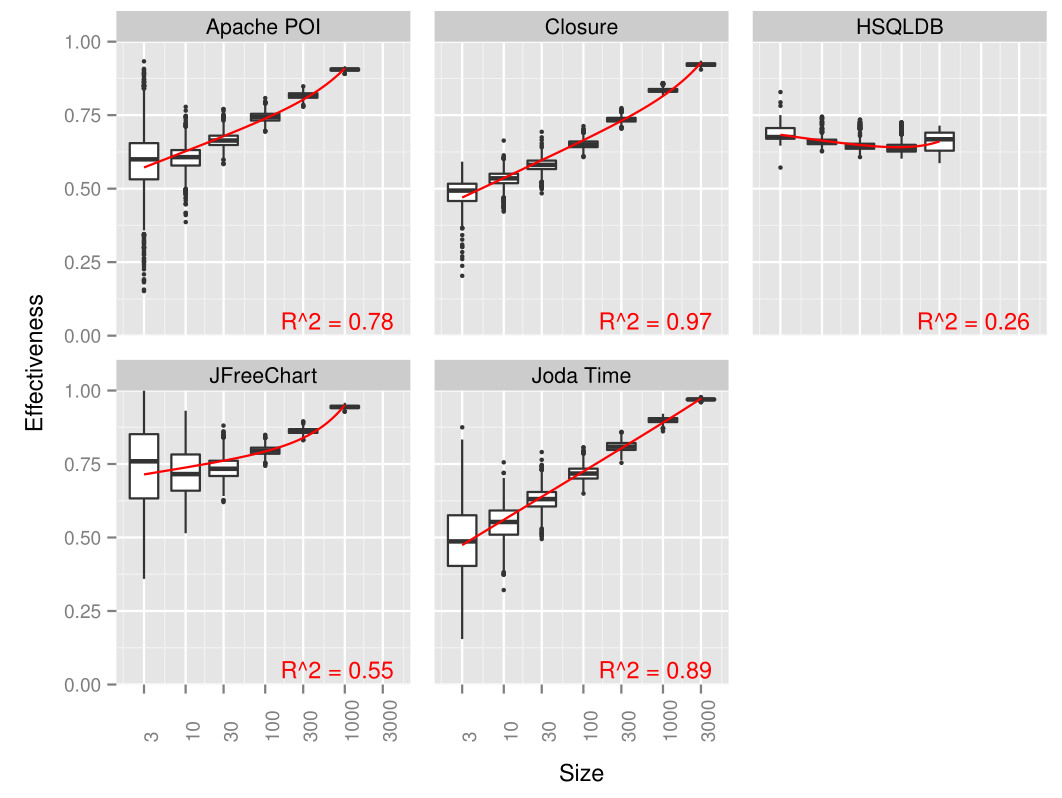
They used R’s lm to fit a linear model to correlate normalized effectiveness with the number of test cases in a test suite.
The resulting fit is shown in the following figure.
The $R^2$ denotes the coefficient of determination.
There was a moderate to very high correlation for all projects except HSQLDB.
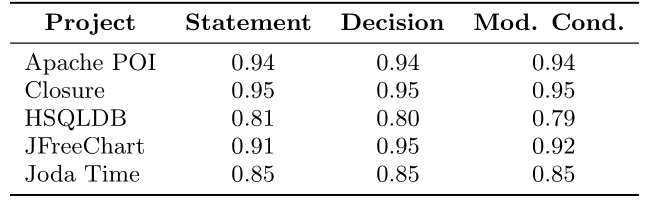
They computed Kendall’s \(\tau\) to measure how the effectiveness of a test suite correlates with its coverage when ignoring suite size influence. Let \(x_i\) \(i\)th test suite’s coverage, \(y_i\) its effectiveness, \(n\) the number of test suites, \(\textit{sgn}\) the signum function:
$$ \tau = \frac{n\sum\_{i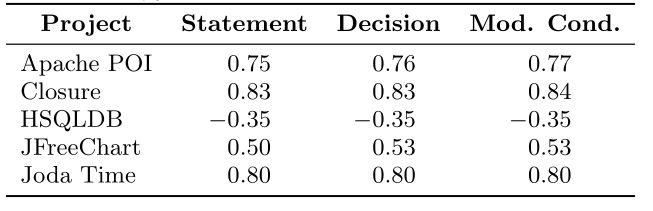
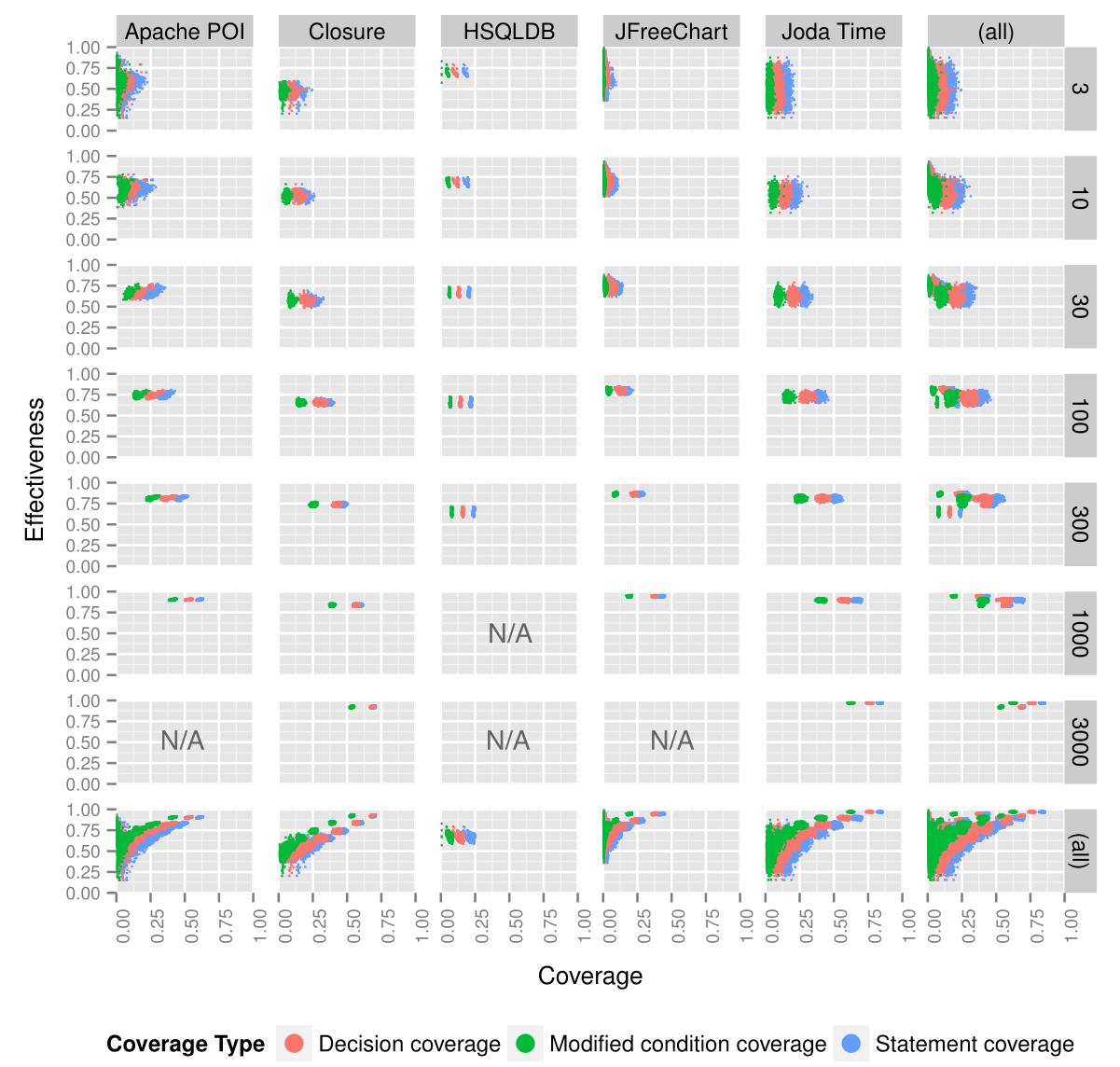
Comparing the correlation between normalized effectiveness and coverage among test suites of the same size, a drop in correlation was observed. The following figures plot normalized effectiveness against coverage, with numbers on the right indicating the number of test cases in a suite.
While a large number of test cases does not necessarily ensure high effectiveness, the empirical study shows a moderate to high correlation between the size of a test suite and its effectiveness. Is the number of test cases a better indicator of effectiveness than code coverage?