Poly-Encoders: Architectures and Pre-Training Strategies for Fast and Accurate Multi-Sentence Scoring (2019)
February 24, 2024For tasks matching input sequences with labels, current state-of-the-art approaches focus on using BERT models for pre-training. Two common encoding approaches are Cross-encoders (Wolf et al.), which concatenate input sequences and candidate labels into a single vector, and produce candidate-sensitive embeddings, and Bi-encoders (Mazaré et al.), which encode input sequences and candidate labels separately. In Bi-encoders, the score is the dot-product of the two embeddings. While Cross-encoders are more accurate than Bi-encoders, Bi-encoders are faster.
Poly-encoders aim to balance speed and accuracy. The following architecture comparison figure is cited from the paper. Poly-encoders aim to attain the balance between inference speed and accuracies.
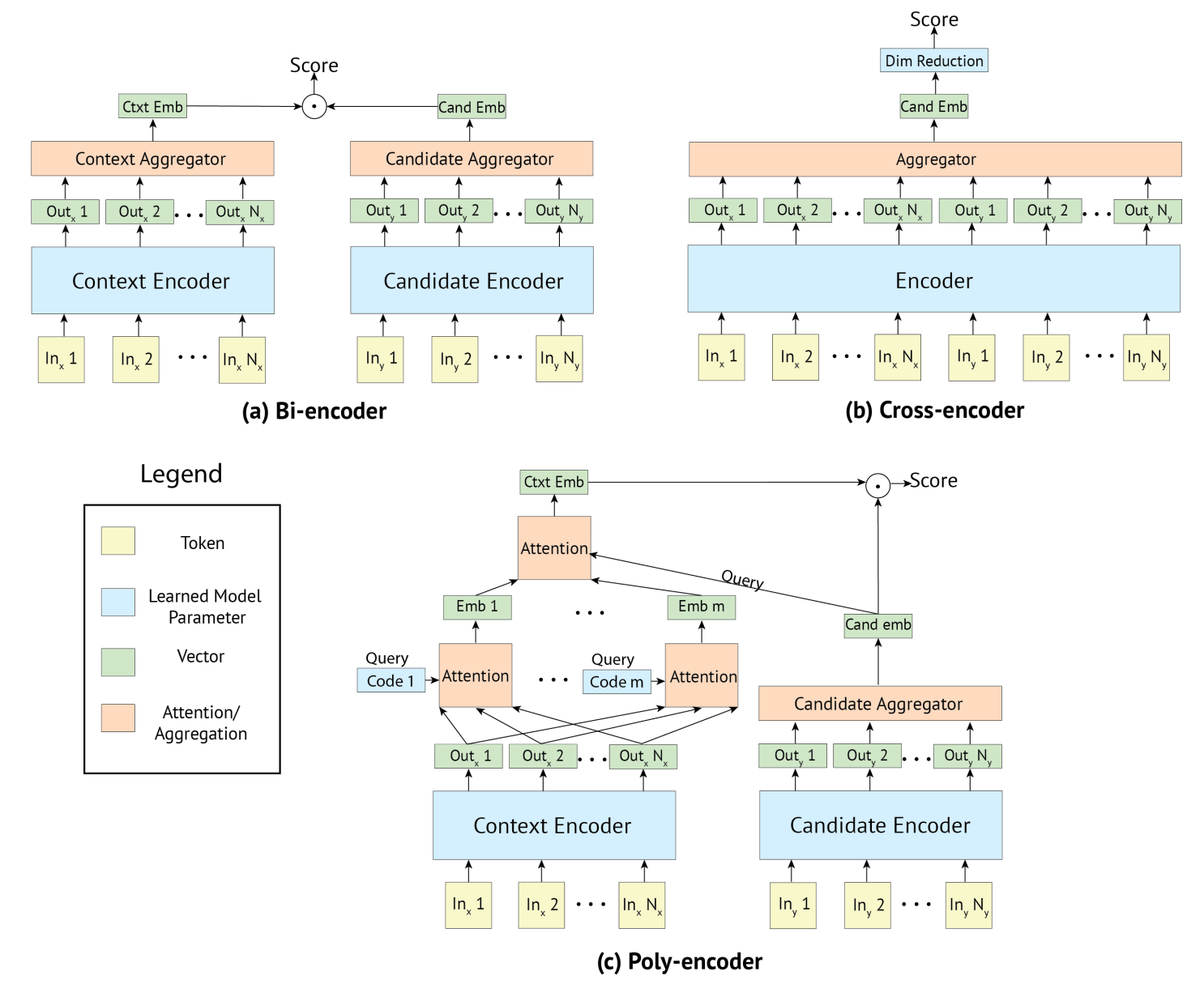
The Poly-encoder generates candidate label embeddings without input sequences like Bi-encoders.
A Bi-encoder uses special tokens [S] and segment tokens like BERT.
To resemble the procedure of pre-training, Bi-encoders surround the input and label by the special token [S], and assign the segment token for features with them.
The Poly-encoder represents an input sequence with \(m\) vectors \((y^1_{\textit{ctxt}}\dots y^m_{\textit{ctxt}})\) using \(m\) attention mechanisms.
$$ \begin{align*} y^i\_{\textit{ctxt}}&=\sum\_jw^{c\_i}\_jh\_j\\\\ (w\_1^{c\_i},\dots , w\_N^{c\_i})&=\text{softmax}(c\_i\cdot h\_1,\dots , c\_i\cdot h\_N) \end{align*} $$where \((h_1,\dots, h_N)\) is the output of Context Encoder in the figure, and context codes \((c_1,\dots,c_m)\) function as the query of the QKV attention mechanism. The context codes are randomly initialized, and learnt during fine-tuning. Finally, the Poly-encoder inputs \((y^1_{\textit{ctxt}}\dots y^m_{\textit{ctxt}})\) and a candidate label \(y_{\textit{cand}_i}\) to the subsequent attention mechanism after the \(m\) ones:
$$ y\_{\textit{ctxt}}=\sum\_iw\_iy^i\_{\textit{ctxt}}\ \ \ \ \text{where}\ \ \ \ (w\_1,\dots ,w\_m) = \text{softmax}(y\_{\textit{cand}\_i}\cdot y^1\_{\textit{ctxt}}, \dots , y\_{\textit{cand}\_i}\cdot y^m\_{\textit{ctxt}}) $$