メモ A Survey on Data Collection for Machine Learning(2018)
October 26, 2019機械学習に使う教師データに関するサーベイ論文であり、機械学習や自然言語処理などのデータの応用分野だけでなく、データの管理にまつわる分野の調査も含まれているところに特徴がある。 データの管理に着目している理由は、深層学習の発展によって必要な教師データが増えたことで、データの管理の課題が顕在化してきたからである。
調査範囲は、次の図が示すように、大きく3つに別れる。それぞれは、データの取得、データへのラベル付け、既存のデータやモデルの改善に分類される。青色の単語はデータ管理の分野である。さらに下の流れ図は、これらの分野の技術を適用すべき状況を整理している。ただし、6節の今後の課題にあるように、流れ図は不完全なものであり、今後洗練される必要があるとされている。
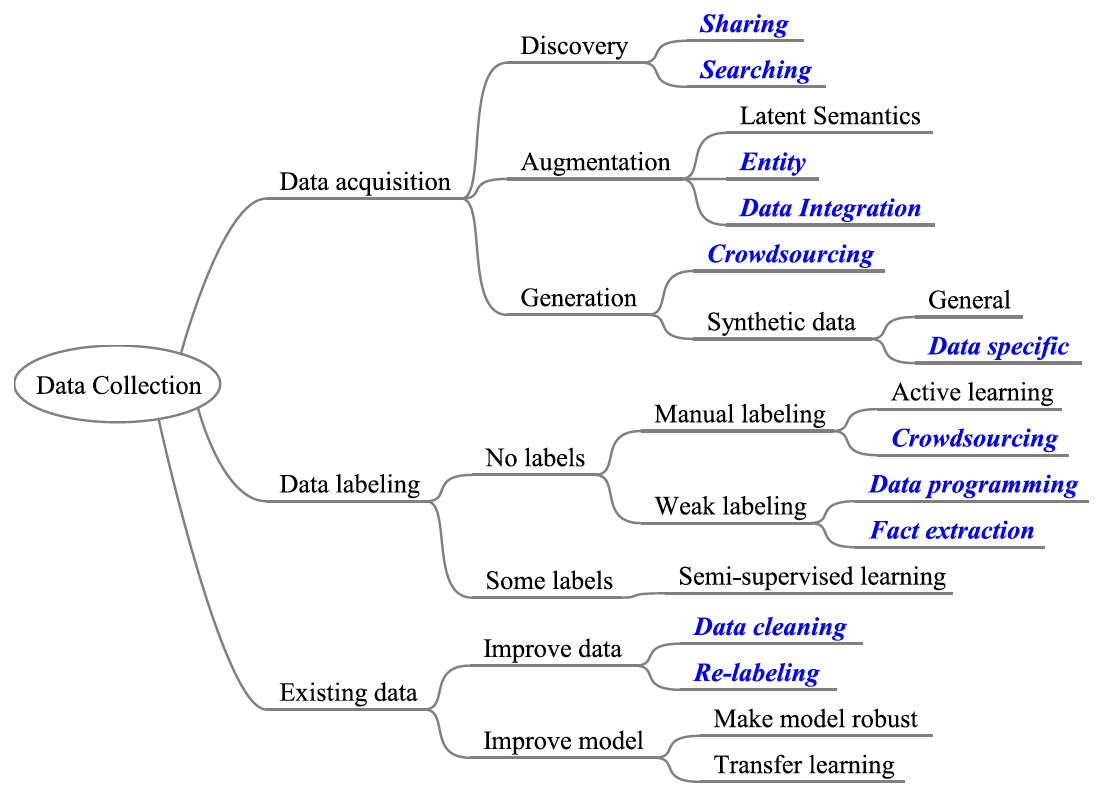
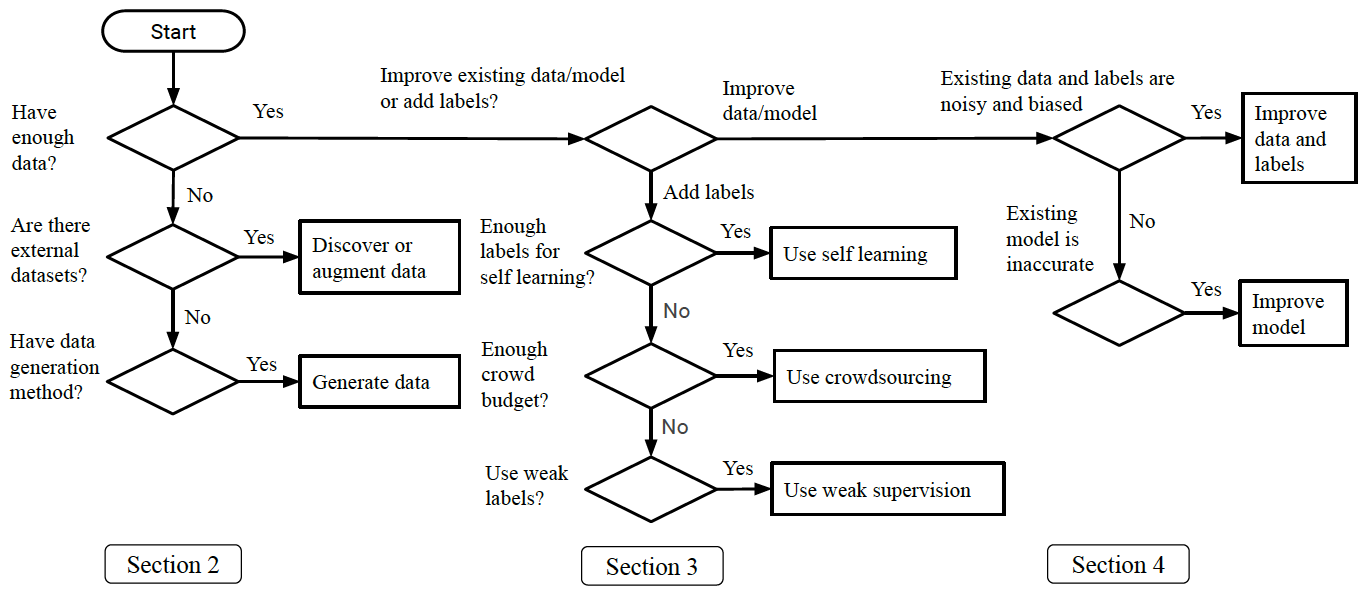
取りあげられた論文の中で気になったものを以下にとりあげる。
- Searching
- WebTables: Webクローリングで収集した大量のHTML形式の表をもとに、属性を入力として共起する属性や類義語を推定する、入力したスキーマから類似の存在するスキーマを提示する、といった検索機能を構築する。ここでのスキーマは表の順序つきのヘッダのリストをさす。
- Entity
- InfoGather: データが欠落しているテーブルを与えると、Web上に存在するテーブルとスキーマ同士を比べることで、欠落を補完する。
- Data Integration
- Hamlet system: 関係データベースに格納されたデータを特徴に使うことを前提として、特徴選択においてテーブルを外部キーで結合し特徴を増やすべきか否かを判定するルールを提案した。実験を通して、多くの場合においてテーブル結合が精度に寄与しないことを示した。
- Data specific
- Data cleaning
- HoloClean:データの制約や外部のデータソースを使い、不整合のあるデータが生成される確率を予測し、そのデータを復元するプログラムを生成する。
- ActiveClean: データをきれいにすることでモデルの精度がどれだけ改善するか、及び、データが汚れているかについての尤度を推測し、きれいにすべき標本を反復的に推薦する。
- Re-labeling
- Sheng et al.: 既存の教師データにノイズがあるとデータを増やしても精度が上らない場合があることを示し、既存のデータの品質を上げる必要性を訴えた。
- 論文はこちらからダウンロードできます。
- 図は全て論文中からの引用です。