論文メモ Bag of Tricks for Efficient Text Classification
July 17, 20202016年における分類のSOTAと互角の精度でありながら、格段に高速に学習、推定可能なモデルをfastTextで構築できることを示した。
評価実験には、YFCC100Mのキャプションとタイトルからタグを予測するタスク、8つのデータセットによる感情分析が採用された。
タグの予測では、312116個のユニークなタグをつかい、大きなクラス数でもモデルがうまくはたらくことが確かめられた。
モデルは、単語のbag of n-gramsの平均値で文を分散表現に変換し、それを全結合層、ソフトマックス関数へと渡す。 モデルの図と損失関数を以下に示す。\(A, B\)は重み行列、\(f\)はソフトマックス関数を示す。 式中の\(x_n\)はベクトルに変換された\(N\)件の文書のうちの\(n\)番目の文書、\(y_n\)は\(n\)番目の文書のラベルに対応する。
$$ -\frac{1}{N}\sum^N\_{n=1}y\_n\log (f(BAx\_n)) $$
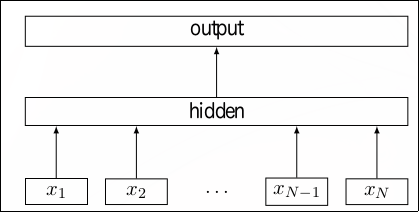
クラス数が多い場合、階層的ソフトマックスによって計算量を削減することができる。 このとき、クラス数を\(k\), 分散表現の次元を\(h\)とすると、計算量を\(O(kh)\)から、学習時では\(O(h\log_2(k)\)、推定時は\(O(h\log_2(k))\)に削減できる。
- 論文をここからダウンロードできます。
- 図は論文から引用されています。