論文メモ Domain Adversarial Training of Neural Networks
April 11, 2020概要
ニューラルネットワークをもちいたドメイン適用の論文である。 ソースドメインのラベルつきデータと目標ドメインのラベルのないデータでモデルを訓練し、目標ドメインに対する分類性能を引きあげる。 目的関数は、ソースドメインの分類器の目的関数とデータのドメインを判定する識別器の目的関数からなる。 後者は、前者の正則化項としてはたらく。 これにより、ドメイン間に共通する特徴からソースドメインのデータのラベルを高い性能で予測できるようになる。 目標関数から、ドメイン間のデータの分布が近いほど、目標ドメインのデータでも高い分類性能を発揮する。 先行研究との違いは、できるだけ共通するする特徴で分類するという着想を、通常の分類と同じく、確率的勾配降下法で実現したところにある。
アーキテクチャ
手法の着想は、できるだけドメイン間で共通する特徴を使うことで目標ドメインのデータに対する分類性能を確保することにある。 入力がとりえる値の範囲\(X\)とラベルの種類\(Y=\{0, 1, \dots , L-1\}\)はソースドメイン\(\mathcal{D}_S\)と目標ドメイン\(\mathcal{D}_T\)間で等しい。 異なるのは、その分布\(\(X \times Y\)\)である。 これを次の式で表すと、
$$ S=\\{(\boldsymbol{\rm x}\_i, y\_i)\\}\_{i=1}^n \sim (\mathcal{D}\_S)^n; T=\\{\mathcal{x}\_i\\}\_{i=n+1}^N \sim (\mathcal{D}\_{T}^X)^{n'} $$となる。
アーキテクチャは、\(D\)次元の特徴を抽出するfeature extractor \(G_f: X\rightarrow \mathbb{R}^D\), label predictor \(G_y: \mathbb{R}^D \rightarrow [0, 1]^L\), 隠れ層の出力からドメインを識別するdomain classifier \(G_d: \mathbb{R}^D \rightarrow [0, 1]\)から構成される。
アーキテクチャの全体像を次の図に示す。
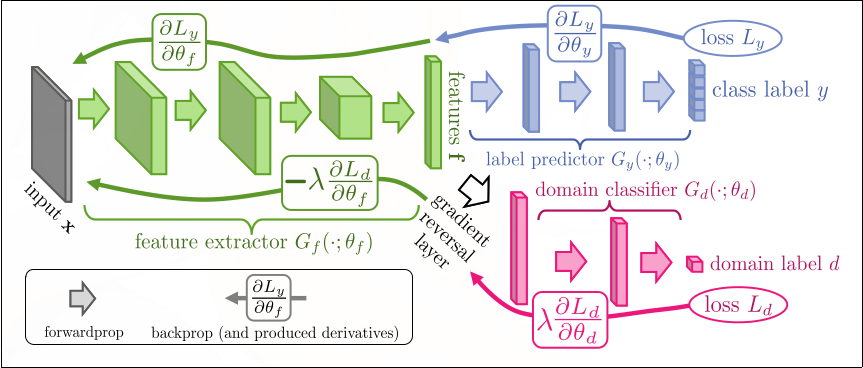
パラメタを\(\theta\), label predictorとdomain classifierの損失関数を\(\mathcal{L}_y, \mathcal{L}_d\), ハイパーパラメタを\(\lambda\)とすると、目的関数は次のようになる。\(d_i\)は\(i\)番目の標本のドメインを示す。
$$ \begin{align} E(\theta\_f, \theta\_y, \theta\_d) &= \frac{1}{n}\sum^n\_{i=1}\mathcal{L}\_y(G\_y(G\_f(\boldsymbol{\rm x}\_i;\theta\_f);\theta\_y), y\_i) \\\\ &-\lambda\left(\frac{1}{n}\sum\_{i=1}^n\mathcal{L}\_d(G\_d(G\_f(\boldsymbol{\rm x}\_i;\theta\_f);\theta\_d), d\_i) + \frac{1}{n'}\sum\_{i=n+1}^N\mathcal{L}\_d(G\_d(G\_f(\boldsymbol{\rm x}\_i;\theta\_f);\theta\_d), d\_i)\right) \end{align} $$学習では次の\(\hat{\theta_f}, \hat{\theta_y}, \hat{\theta_d}\)からなる鞍点を探す。
$$ \begin{align} (\hat{\theta\_f}, \hat{\theta}\_y)&=\underset{\theta\_f, \theta\_y}{\operatorname{argmin}}E(\theta\_f, \theta\_y, \hat{\theta}\_d)\\\\ \hat{\theta\_d}&=\underset{\theta\_d}{\operatorname{argmax}}E(\hat{\theta}\_f, \hat{\theta}\_y, \theta\_d)\\\\ \end{align} $$鞍点に近づけるために、学習率\(\mu\)でパラメタを更新する。
$$ \begin{align} \theta\_f &\leftarrow \theta\_f - \mu \left(\frac{\partial\mathcal{L}\_y^i}{\partial\theta\_f}-\lambda \frac{\partial \mathcal{L}\_d^i}{\partial \theta\_f}\right)\\\\ \theta\_y &\leftarrow \theta\_y - \mu\frac{\partial\mathcal{L}\_y^i}{\partial\theta\_y} \\\\ \theta\_d &\leftarrow \theta\_d - \mu\frac{\partial\mathcal{L}\_d^i}{\partial\theta\_d} \\\\ \end{align} $$\(\theta_f\)については、括弧中の符号がマイナスであるため、他のパラメタと異なり、そのままでは確率的勾配降下法を使うことができない。 そこで、feature extractorとdomain classifierの間にgradient reversal layerを挿入する。 これは、パラメタのない恒等写像の層\(\mathcal{R}\)であり、予測時には、恒等写像としてはららき、学習時には出力からの勾配の符号を反転させて、入力層に流す。
$$ \begin{align} \mathcal{R}(\boldsymbol{\rm x})&=\boldsymbol{\rm x}\\\\ \frac{d\mathcal{R}}{d\boldsymbol{\rm x}}&=-\boldsymbol{\rm I} \end{align} $$この層をもちいると、確率的勾配降下法で学習できる目的関数\(\tilde{E}\)の学習で\(E\)の鞍点を求めることができる。
$$ \begin{align} \tilde{E}(\theta\_f, \theta\_y, \theta\_d) &= \frac{1}{n}\sum^n\_{i=1}\mathcal{L}\_y(G\_y(G\_f(\boldsymbol{\rm x}\_i;\theta\_f);\theta\_y), y\_i) \\\\ &-\lambda\left(\frac{1}{n}\sum\_{i=1}^n\mathcal{L}\_d(G\_d(\mathcal{R}(G\_f(\boldsymbol{\rm x}\_i;\theta\_f));\theta\_d), d\_i) + \frac{1}{n'}\sum\_{i=n+1}^N\mathcal{L}\_d(G\_d(\mathcal{R}(G\_f(\boldsymbol{\rm x}\_i;\theta\_f));\theta\_d), d\_i)\right) \end{align} $$- 論文はこちらからダウンロードできます。
- 画像は論文から引用されています。