Improving Language Understanding by Generative Pre-Training (2018)
November 16, 2025 (Originally posted on August 7, 2020)Improving Language Understanding by Generative Pre-Trainingは教師なしの事前学習であり、GPTシリーズの最初のモデルにあたる。 12の自然言語処理タスクのうち9つについて、事前学習したモデルの出力を1層の全結合層に入力するファインチューニングで、当時のSoTAを上まわる性能を発揮した。
ネットワークは、transformerのデコーダーであり、Attention Is All You Needのエンコーダーは含まれない。 ファインチューニングでは、特徴の入力を事前学習のデータ形式に揃えることで、事前学習とファインチューニングの差異を埋める。 推論タスクであれば前提や仮定、テキストの類似性判定であれば比較する2つのテキストといった異種の特徴をデリミタで連結した系列を作り、モデルに入力する。
事前学習では、コンテキストウィンドウの長さを\(k\),トークン列を\(\mathcal{U}=\{u_1,\dots , u_n\}\)として、コンテキストウィンドウに続くトークンの生起確率を最大化できるように目的関数\(L_1(\mathcal{U})\)を設定する。
$$ L\_1(\mathcal{U})=\sum\_i\log P(u\_i\mid u\_{i-k},\dots , u\_{i-1};\Theta) $$モデルに使われるmulti-layer trasformer decoderは、条件付き確率\(P\)にあてはまるようにパラメタ\(\Theta\)を学習する。 \(0\)番目のtransformerは、コンテキスト \(U=(u_{-k}, \dots, u_{-1})\)に、トークンの埋込み行列 \(W_e\)とトークンの位置の埋込み行列\(W_p\)を線型結合して求まる値\(h_0\)を入力に受け付ける。 後続のtransformerは一つ前のtransformerの出力を引き継ぐ。
$$ \begin{align} h_0&=UW_e+W\_p\\\\ h_l&=\mathtt{transformerblock}(h_{l-1})\forall i \in[1,n]\\\\ P(u)&=\texttt{softmax}(h\_nW^{T}\_{e}) \end{align} $$ファインチューニングでは、最後のtransformerから出力された末尾のトークンを1層の全結合層に入力する。
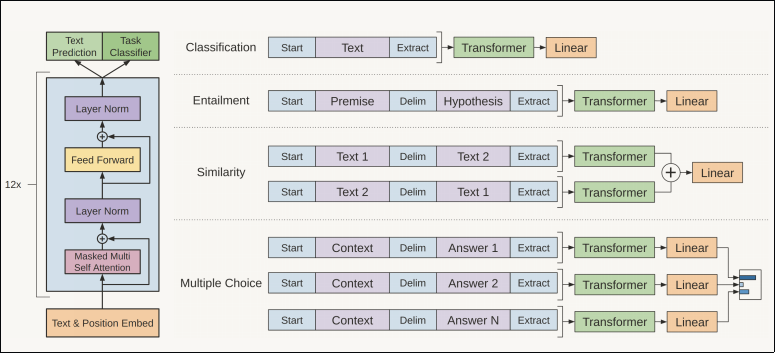
以下の図は、ファインチューニングの学習データ\(\mathcal{C}\)を事前学習の入力形式に合わせてモデルに与える様子を示す。
上の図の右部は、分類、含意関係認識、類似度、Q&Aのタスクにおける入力を示す。
分類以外は全て、事例の要素をデリメタを挟んで隣接させ、モデルにあたえている。
 教師データの事例のトークン列を\(x^1,\dots , x^m\), 最終層の出力を\(h_l^m\), 全結合層のパラメタを\(W_y\), 学習時には次の\(L_2(\mathcal{C})\)を最大化する。
また、汎化性能や学習の収束時間を改善するために、事前学習の目的関数に重み\(\lambda\)を添えた\(L_3(\mathcal{C})\)を目的関数に設定することもできる。
教師データの事例のトークン列を\(x^1,\dots , x^m\), 最終層の出力を\(h_l^m\), 全結合層のパラメタを\(W_y\), 学習時には次の\(L_2(\mathcal{C})\)を最大化する。
また、汎化性能や学習の収束時間を改善するために、事前学習の目的関数に重み\(\lambda\)を添えた\(L_3(\mathcal{C})\)を目的関数に設定することもできる。