Regression Shrinkage and Selection via the Lasso
June 12, 2022Lasso(least absolute shrinkage and selection operator)を提案した論文で、特定の回帰係数を0にする正則化項により、モデルを解釈しやすくする。 Subset selectionはデータの変化に敏感で、学習結果が安定しない。 Ridge回帰は、回帰係数を全体的に小さくすることで正則化項の制約をみたすため、説明変数を減らしてモデルを解釈しやすくはしない。 線形回帰のモデルから人工的に生成し、Lasso回帰、Subset selection, Ridge回帰を比較した。 結果、もとのモデルの少数から中程度の回帰係数の絶対値が小さく残りが0のときに、Lasso回帰の精度が最も高かった。 絶対値の大きい少数の回帰係数と0の回帰係数のときはSubset selectionが、絶対値の小さい回帰係数が多いときにRidge回帰の精度が最も高かった。
平均を0, 分散を1に標準化した説明変数\(\boldsymbol{\rm x}^i = (x_{i1}, \dots , x_{ip})^\top\)からなるデータセットを\((\boldsymbol{\rm x}^i, y_i), i= 1, 2, \dots , N\)とおく。 \(\hat{\boldsymbol{\beta}}=(\hat{\beta}_1,\dots , \hat{\beta}_p)^\top\)とおくと、Lasso回帰のパラメタ\((\hat{\alpha}, \hat{\beta})\)は、\(t>0\)として
$$ \begin{align} (\hat{\alpha}, \hat{\beta}) = {\operatorname{argmin}} \left\\{\sum^N\_{i=1}\left(y\_i-\alpha -\sum\_j\beta\_jx\_{ij}\right)^2\right\\}&\text{subject to} \sum\_j\mid\beta\_j\mid \le t \end{align} $$と定義できる。
\(\hat{\beta}^o_j\)を正則化項のない場合の回帰係数、\(\boldsymbol{\rm X}\)を\(n\times p\)で\(ij\)の要素が\(x_{ij}\)で\(\boldsymbol{\rm X}^\top \boldsymbol{\rm X}=\boldsymbol{\rm I}\)である行列とし、目的変数が直交であるとする。このとき\(\gamma\)を\(\sum\mid \hat{\beta}_j\mid=t\)から決まる値として、
$$ \hat{\beta}\_j = \text{sign}(\hat{\beta}^o\_j)(\mid \hat{\beta}^o\_j\mid -\gamma)^+ $$となる。 \(\gamma\)の値が大きいほど、0になる回帰係数の数が増える。
説明変数が直交している場合のほか、\(p=2\)の場合についても、回帰係数が0になる理由にも説明がある。
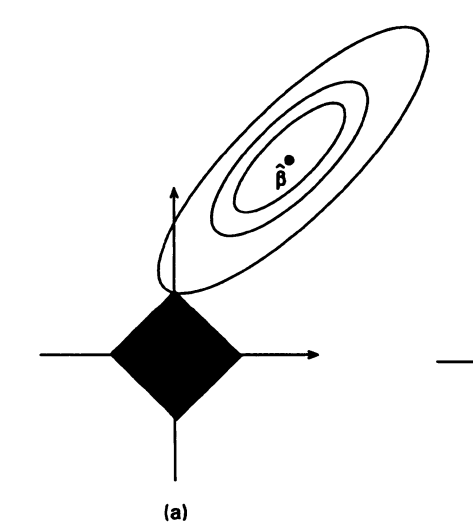
下図は、説明変数の数が2で、正則化項のない回帰係数の値が正則化項のあるときの領域外にある様子をしめしている。
このとき、ほとんどの\(\hat{\beta}\)において、\(\beta\)からの距離の等高線と領域が領域の頂点が接するため、回帰係数の1つが0になる。
論文へのリンク
画像は論文から引用したものです。