2024年11月のruncの実装
December 8, 2024runcは抽象度の低いコンテナのランタイムであると同時に、そのランタイムを操作するCLIでもある。 もともとruncはdockerの一部だったが、2015年にdockerからのスピンアウトされた。 containerdがruncでコンテナの操作するので、今でもdockerはruncでコンテナを操作していることになる。 この記事は、runcの実装に使われているLinuxの機能を紹介する。
runcの使い方
runcでコンテナを起動する場合、イメージはいらず、コンテナの/以下がホストにあればよい。
たとえば、次のコマンドでコンテナを起動できる。
mkdir rootfs
# copy the / in the busybox to rootfs
docker export $(docker create busybox) | tar -C rootfs -xvf -
# generate ./config.json
runc spec
# create the container and attach to the launched /bin/sh in the container
runc --root /tmp/runc run
コンテナを起動する前にbusyboxから/をローカルにコピーし、コンテナ内の/bin/shにアタッチしている。
runcのrunの実装
runcには複数のサブコマンドがあり、runはコンテナを作り、そのコンテナを起動する。
前述のコマンドを実行するときのruncの様子を以下の図示する。
runは非同期にrunc initコマンドを実行し、このプロセスがexecveでコンテナのPID 1のプロセスになる。

ホストとコンテナ間の標準IO
ホストとコンテナ間の標準IOの通信は疑似端末(pty)で実装されている。
ptyの実体は、一方の書き込みが他方の読み込みになる双方向通信可能なキャラクターデバイスのペアであり、ペアの要素はマスターとスレーブとよばれる。
マスターは/dev/ptmxであり、このファイルを開くと/dev/ptsの下にキャラクターデバイスがスレーブとして作られる。
initが、マスターとスレーブを作り、socketpairで作られたソケットの組を介してマスターをホストに送る。
ソケットの作るのはホストであり、setupIO関数の以下の箇所でソケットの組を作る。
parent, child, err := utils.NewSockPair("console")
if err != nil {
return nil, err
}
childソケットをinitに渡すために、runはソケットをinitを実行するCmd構造体のExtraFilesの配列に入れる。
Cmdで呼びだされたプロセスはExtraFilesで指定されたファイルを開いた状態で開始し、ExtraFilesのi番目の要素のファイル記述子は3+iになる。
newParentProcess関数の以下の箇所で、childソケットに束縛されたp.ConsoleSocketをExtraFilesに入れ、環境変数_LIBCONTAINER_CONSOLEでinitプロセスにファイル記述子を伝える。
cmd.ExtraFiles = append(cmd.ExtraFiles, p.ExtraFiles...)
if p.ConsoleSocket != nil {
cmd.ExtraFiles = append(cmd.ExtraFiles, p.ConsoleSocket)
cmd.Env = append(cmd.Env,
"_LIBCONTAINER_CONSOLE="+strconv.Itoa(stdioFdCount+len(cmd.ExtraFiles)-1),
)
}
initは、/dev/ptmxを開き、以下のSendRawFd関数の中で、マスターのファイル記述子をchildソケットに書き込む。
// SendRawFd sends a specific file descriptor over the given AF_UNIX socket.
func SendRawFd(socket *os.File, msg string, fd uintptr) error {
oob := unix.UnixRights(int(fd))
return unix.Sendmsg(int(socket.Fd()), []byte(msg), oob, nil, 0)
}
initはスレーブを以下のdupStdio関数で標準IOとエラー出力に複製する。
// dupStdio opens the slavePath for the console and dups the fds to the current
// processes stdio, fd 0,1,2.
func dupStdio(slavePath string) error {
fd, err := unix.Open(slavePath, unix.O_RDWR, 0)
if err != nil {
return &os.PathError{
Op: "open",
Path: slavePath,
Err: err,
}
}
for _, i := range []int{0, 1, 2} {
if err := unix.Dup3(fd, i, 0); err != nil {
return err
}
}
return nil
}
また、initは次のSetctty関数でスレーブを制御端末にする。
func Setctty() error {
if err := unix.IoctlSetInt(0, unix.TIOCSCTTY, 0); err != nil {
return err
}
return nil
}
他方、runプロセスはrecvtty関数で
recvmsgで受け取ったマスターをepollで監視し、recvtty関数の以下のコードで、マスターから読みとったストリームを標準出力にコピーし、ホストの標準出力をマスターにコピーする。
go func() { _ = epoller.Wait() }()
go func() { _, _ = io.Copy(epollConsole, os.Stdin) }()
t.wg.Add(1)
go t.copyIO(os.Stdout, epollConsole)
名前空間
コンテナ同士やホストとコンテナ間でネットワークやマウントポイントなどのリソースを隔離、共有する機能は、名前空間で実装されている。 おなじ名前空間にあるプロセス同士で端末のリソースを共有し、プロセスは別の名前空間で消費されるリソースの影響を受けない。 プロセスからは、おなじ名前空間にあるプロセスだけで端末のリソースを占有しているようにみえる。 たとえば、2つの名前空間のプロセスに同じPIDが割りあてることができる。
プロセスの名前空間を変更するAPIにclone, setns, unshareがある。
cloneは新しいプロセスを作る関数であり、新しい名前空間を作り、子プロセスをその名前空間の中に生成する。
setnsは、setnsを呼びだしたスレッドを既存の名前空間に移動する。
unshareは、新しく名前空間を作って呼出したプロセスをその名前空間に移す。
Cのnsexec関数でinitプロセスの名前空間が変更される。
nsexecは、以下のnsenter.goでGoのランタイムが始まる前に呼び出される。
//go:build linux && !gccgo
package nsenter
/*
#cgo CFLAGS: -Wall
extern void nsexec();
void __attribute__((constructor)) init(void) {
nsexec();
}
*/
import "C"
README.mdにはGoがマルチスレッドだからCで名前空間を切り換えると書かれてある。
これは、setnsは呼出元のスレッドの名前空間を切り換えるが、スレッドが複数あると、すべてのスレッドでsetnsを呼ぶ必要があるということだろう。
nsexecは、2度cloneを呼出し、initの名前空間を変更する。
以下にnsexecの処理を図示する。
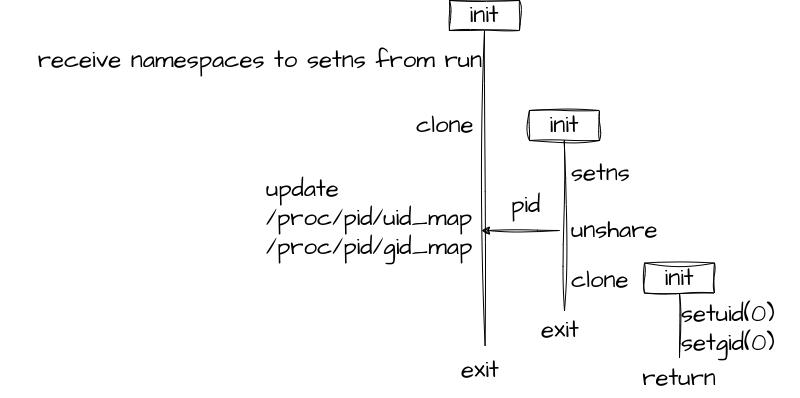 最後に生成されたプロセスのみ
最後に生成されたプロセスのみreturn文を実行し、Goのmain関数が続き、残るプロセスはGoのランタイムを開始することなく終了する。
nsexecは、ある名前空間の中でinitプロセスにPID1を割り当てるためにcloneを実行する。
unshareも新しい名前空間を作成する関数であるが、unshareは呼出元のプロセス名前空間を変更できないためにcloneが使わているのだろう。
cloneにはCLONE_PARENTフラグを渡し、新しい子initの親プロセスをcloneを呼出したプロセスの親プロセスにする。
左のinitプロセスの親はrunなので、return文を実行し、Goのmain関数に続く最後のinitプロセスの親もrunになる。
最後のinitの親をrunにすることで、initのSIGCHLDをrunに届けることができる。
最初にcloneされた図の真ん中にあるinitプロセスは、setnsで既存の名前空間に参加したり、unshareで新しく作った名前空間に移動したりする。
/proc/<pid>/uid_map, /proc/<pid>/gid_mapはinitのユーザID, グループIDに対応するホストのユーザIDグループIDを定義したファイルであり、initのユーザーやグループは、ホストからはファイルが対応づけたホストのユーザやグループのようにみえる。
ルートファイルシステム
pivot_rootでinitのルートファイルシステムをコンテナのディレクトリのルートに置き換える。
以下のコードはpivot_rootの実行例であり、rootfsのトップディレクトリをルートファイルシステムに設定している。
cd rootfs && mkdir put_old
# run /bin/sh in a a new namespace
unshare -mpfr /bin/sh
# the first argument of pivot_root must be a mount point
mount --bind $(pwd) $(pwd)
# Place the original root in put_old. Can be unmounted later
pivot_root $(pwd) $(pwd)/put_old
ホストのプロセスとコンテナの違い
ここまでで、ほかのプロセスとコンテナを隔離するために使われた技術は名前空間とpivot_rootがあった。
ほかにもcgroupなどのコンテナを隔離するために使わている技術があるが、cgroupも名前空間やpivot_rootと同様にコンテナに用途を限定した技術ではない。
runcの実装をみれば、コンテナの実体は、通常のプロセスとは全く違う特殊なプロセスではなく、cgroup, 名前空間, pivot_rootでほかのプロセスから隔離されたプロセスにすぎないと思えてくるだろう。