TelegraphCQ: Continuous Dataflow Processing for an Uncertain World (2003)
March 22, 20242005年、StonebrakerとÇetintemelは、“One Size Fits All”で、ストリーミングデータを例に、あらゆる種類のデータをDMBSで管理できなくなったと主張した。 “One Size Fits All"については過去の記事で紹介した。 2003年に発表されたTelegraphCQは、そのようなドメイン特化のデータベースが必要とされはじめた初期のストリーミングデータのためのデータベースである。
RDBMSがストリーミングデータを苦手とする理由は、ストリーミングデータが継続的かつ不定期に発生することにある。 センサーデータを監視するアプリケーションなどは、ストリーミングデータを遅滞なく処理しなければならない。 到着したデータをリアクティブに処理するために、到着したばかりのデータを既存のクエリに適用するようにデータを転送する必要がある。 また、遅延のないように、複数のクエリ間に共通の処理を個別に処理せず、処理の結果を共有するほうが望ましい。 RDBMSのクエリは、クエリ発行以前からあるデータを処理し、また、データの統計情報やインデックスで最適化されるので、ストリーミングデータには適さない。
以上の背景から開発されたTelegraphCQは、Telegraphのアーキテクチャ上の課題を解決するために、PostgresSQLを再利用して実装された。
以下の図は、当時のPostgreSQLのアーキテクチャであり、灰色の箇所がTelegraph CQのために改造されたモジュールを示す。
濃い灰色のほうが薄い灰色よりも手を加えられている。
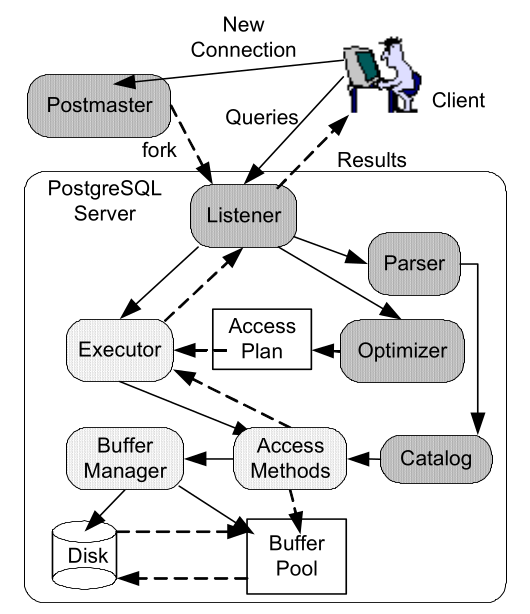 Postmasterは、クライアントのコネクションに応じてサーバのプロセスをフォークする。
Listenerは、コネクションを通したリクエストに対してクライアントにデータを返す。
到着したクエリは、パース、最適化、コンパイル後に実行計画され、Executerで処理される。
Postmasterは、クライアントのコネクションに応じてサーバのプロセスをフォークする。
Listenerは、コネクションを通したリクエストに対してクライアントにデータを返す。
到着したクエリは、パース、最適化、コンパイル後に実行計画され、Executerで処理される。
TelegraphCQは、メモリを共有したFrontend, Executor, Wrapperの3プロセスかなる。
以下に、TelegraphCQのアーキテクチャの図を示す。
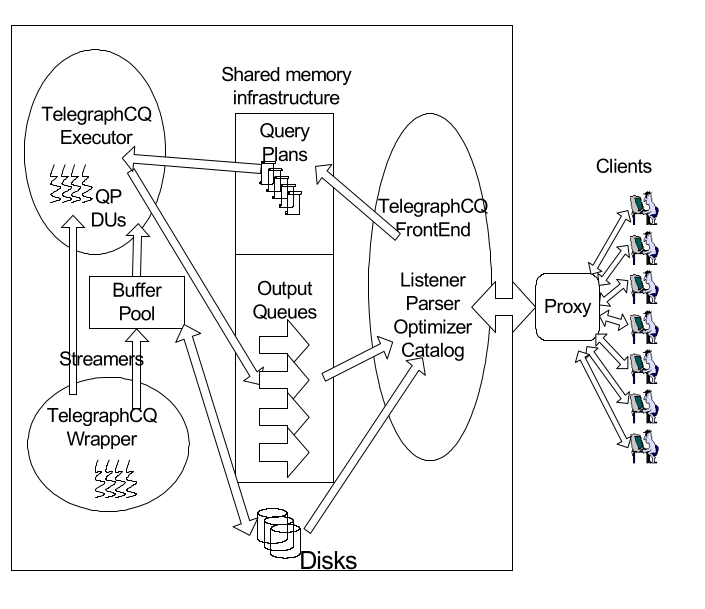 Postmasterは、新しいコネクションをうけつけると、FrontEndプロセスをフォークする。
各コネクションにある複数のカーソルを同時にあうために、proxy serviceを利用する。
FrontendとExecutorは、共有メモリ空間にあるキューを介して、リクエストと結果を交換する。
Frontendはクエリを実行計画に相当するAdaptive planにまで解析したあと、adaptive planをQuery Plansに入力する。
Executorは、クエリの結果をOutput Queueに追加し、Listnerに結果を返す。
Wrapperは、ストリーミングデータを受信するプロセスであり、ブロッキング操作やディスクへのアクセスを避けつつ、Executorにデータを供給する。
Postmasterは、新しいコネクションをうけつけると、FrontEndプロセスをフォークする。
各コネクションにある複数のカーソルを同時にあうために、proxy serviceを利用する。
FrontendとExecutorは、共有メモリ空間にあるキューを介して、リクエストと結果を交換する。
Frontendはクエリを実行計画に相当するAdaptive planにまで解析したあと、adaptive planをQuery Plansに入力する。
Executorは、クエリの結果をOutput Queueに追加し、Listnerに結果を返す。
Wrapperは、ストリーミングデータを受信するプロセスであり、ブロッキング操作やディスクへのアクセスを避けつつ、Executorにデータを供給する。
画像は論文中より引用しました。
雑記
RDBMSは高機能なストレージ機能とクエリ(=処理)の機能を提供し、TelegraphCQはPostgreSQLを改造することで両方の機能をそなえる。 一方、今日のストリーミングデータの処理においては、データの保存にKafkaのようなキューイングシステム、その処理にSparkやStormのようなストレージ機能のない分散処理フレームワークを使用し、2つの機能を別々のミドルウェアにまかせている。 DMBSを改造すればドメイン特化のデータベースを実装できると期待しTelegraphCQが開発されたは、今日からみれば、まだOne Size Fits Allの考えがどこか残っていたかのように感じる。