Unsupervised Pretraining for Sequence to Sequence Learning(2017)
February 16, 2020概要
事前学習とファインチューニングによりseq2seqの汎化性能を改善する手法を提案した論文である。 encoderの重みを学習済み言語モデルの重みで初期化する。 decoderについても、encoderと別の言語モデルを用意し、その重みで初期化する。 ただし、工夫のないファインチューニングをすると破滅的忘却が生じてしまう。 そこで、ファインチューニングでは言語モデルとseq2seqの目的関数の両方を学習につかうことで、過学習をさけ、汎化性能を確保する。
アーキテクチャ
言語モデルで重みを初期化する着想は、encoderのないdecoderや出力層のないencoderが言語モデルに似ているという観察に由来する。 実験では、言語モデルに1層のLSTMが採用されている。 encoderとdecoderのembedding層と1層目のLSTMを各言語モデルの重みで初期化する。 seq2seqには3層のLSTMが使われる。 事前学習のほか、後述のresidual connectionsと注意機構を導入することで、わずかであるが一貫した改善がみられた。
Residual connections
decoderの2層目以降は無作為に初期化されるため、ソフトマックス層へ入力されるベクトルは無作為になる。
これを避けるために、以下の図(a)のように、1層目のLSTMの出力からソウトマックス層へのresidual connectionを設ける。
青の背景は、事前学習でえられた重みで初期化された範囲を示す。
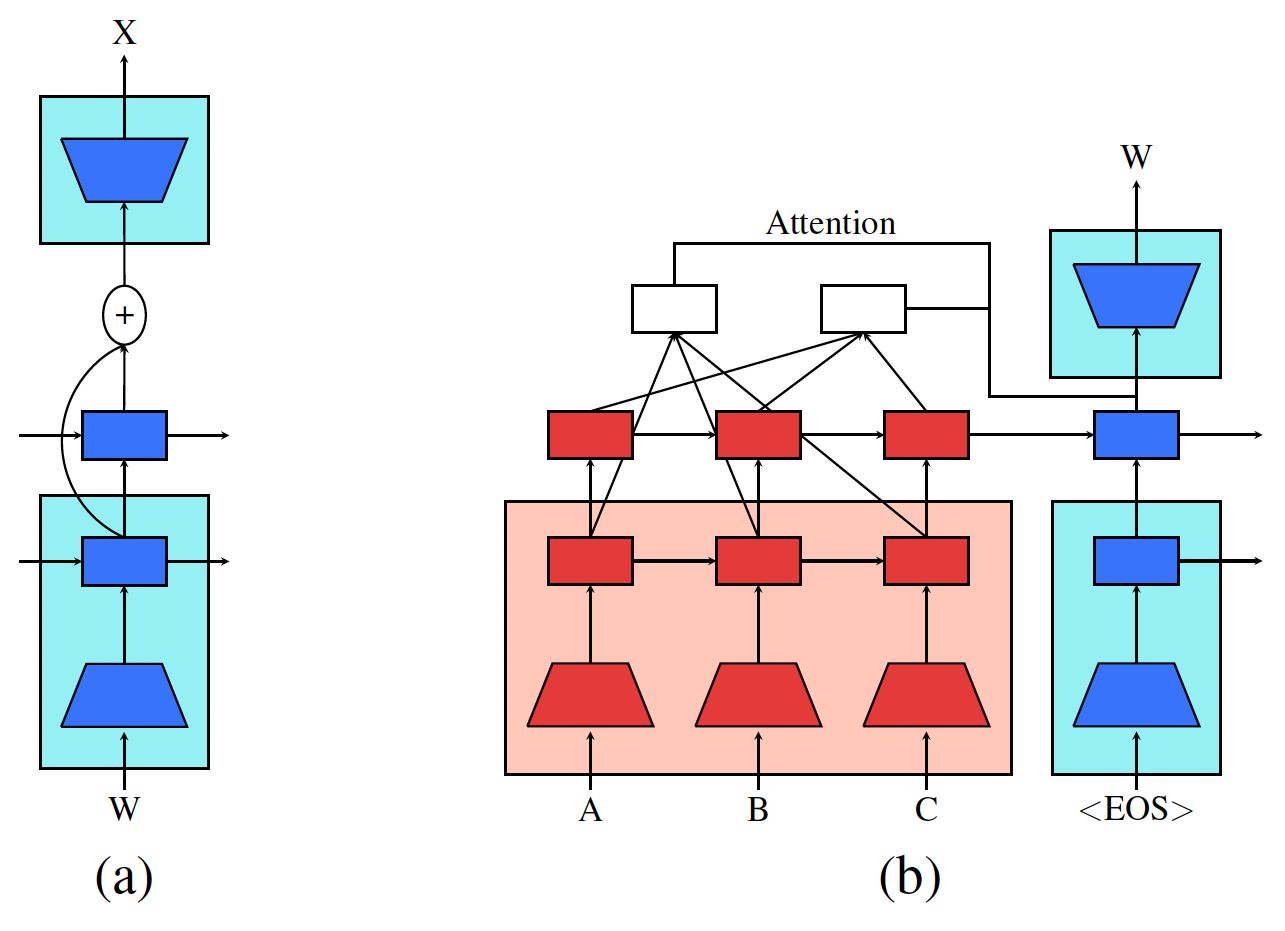
Multi-layer attention
図の(b)のように、encoderにおけるLSTMの最初と最後の層の状態とdecoderのソフトマックスへの入力ベクトル\(q_t\)から文脈ベクトルをつくる。 encoderの1層目の状態を\(h^{1}_1 , \dots , h^1_{T}\), 最後の層の状態を\(h^{L}_1 , \dots , h^L_{T}\)とすると文脈ベクトル\(c_t\)を次のように算出する。
$$ \alpha\_i = \frac{\exp (q\_t \cdot h^{L}\_i)}{\sum^T\_{j=1}\exp (q\_t \cdot h^L\_j)} $$$$ c^1\_{t}=\sum^{T}\_{i=1}\alpha\_ih^1\_{i} $$
$$ c^L\_{t}=\sum^T\_{i=1}\alpha\_ih^L\_{i} $$
$$ c\_t=[c^1\_{t};c^L\_t] $$
- 論文はこちらからダウンロードできます。
- 図はすべて論文から引用されています。