論文メモ Zero-shot Word Sense Disambiguation using Sense Definition Embeddings
October 30, 2020語義曖昧性解消のためのアーキテクチャ, Extended WSD Incorporating Sense Embeddings(EWISE)を発表した。 EWISEは単語の意味をアノテーションしあテキストと辞書を教師データにもちいる。 実験では、辞書にWordNetをつかい、概念同士の上下関係や関係を示す分散表現を獲得する。 学習であたえられていない意味を推定するために、離散値ではなく分散表現でラベルの意味を表現する。
アーキテクチャ
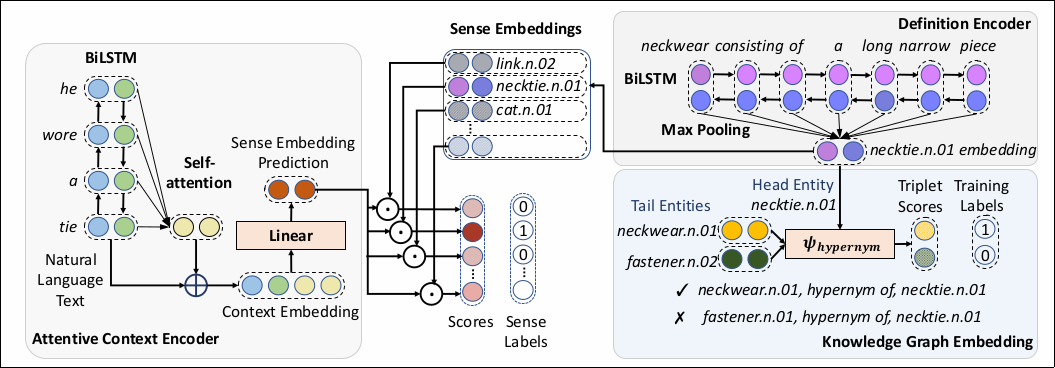
Atentive Context Encoder
Attentive Context Encoderは、入力文を、意味の分散表現のある空間のベクトルに写像する。 はじめに、入力文\(<x^1 \dots x^T>\)を2層の双方向LSTMと注意機構にあたえて文脈依存の分散表現をつくる。 双方向LSTMの順方向の出力を\(h^i_f\)逆方向の出力を\(h^i_b\)とすると注意機構を出力は次の\(r^i\)になる。 \(d_k\)は\(W_qu^i\)や\(W_ku^t\)の次元数をしめす。
$$ u^i=[h^i\_f,h^i\_b] $$$$ \begin{align} e^i\_t&=\text{dot}(W\_qu^i,W\_ku^t);t\in [1, T]\\\\\ a^i&=\text{softmax}\left(\frac{e^i}{\sqrt{d\_k}}\right)\\\\\ c^i&=\sum\_{t\in [1,T]}a^i\_tW\_vu^t\\\\\ r^i&=[u^i, c^i] \end{align} $$\(r^i\)を意味の分散表現に射影する全結合層にあたえ、意味の分散表現\(v^i\)をえる。
$$ v^i=W\_lr^i $$Definition Encoder
単語の定義を2層の双方向LSTMにあたえ、その出力にMax Poolingを適用し、単語の定義をしめす固定長の分散表現を獲得する。 Max PoolingではLSTMの出力について、各次元の最大値を選択する。 以降、Encoderを\(q(\cdot)\)と表記する。
Knowledge Graph Embedding
ナレッジグラフは上位概念\(h\)と下位概念\(t\)の間に関係\(l\)を定義し、学習ではこの3つを示す分散表現\(e_h\), \(e_l\), \(e_t\)を獲得する。 \(f(x)\)を正規化線形関数\(f(x)=\max (0, x)\)、\(\bar{q(h)}\), \(\bar{e_l}\)をそれぞれベクトルを行列に変換、\(\text{vec}\)を行列からベクトルに変換する操作として、次の損失関数\(L_C\)で\(e_{\{h,l,t\}}\)学習する。
$$ \begin{align} \psi\_l(e\_h, e\_t)&=f(\text{vec}(f([\bar{q(h)};\bar{e\_l}]*w))W)e\_t\\\\\ p&=\sigma(\psi\_l(e\_h,e\_t))\\\\\ L\_C&=-\frac{1}{N}\sum\_i(t\_i\log(p\_i) + (1-t\_i)\log(1-p\_i)) \end{align} $$ただし、\(t_i\)は\(h, l, t\)が定義されているときのみ\(1\)、それ以外では\(0\)になる。
WSD
Knowledge graphの学習で獲得した概念の集合を\(S\), \(b\)をパラメタとして、単語の意味上の空間に写像された入力文に対して、ナレッジグラフ上の単語の概念を推定できるように学習する。 ただし、\(z^i\)は\(S\)上の意味を示すone-hotベクトルである。
$$ \begin{align} \hat{p}\_j^i&=\text{softmax}(\text{dot}(v^i,\rho\_j)+\text{dot}(b,\rho\_j));\rho\in S\\\\\ L^i\_{wsd}&=-\sum\_j(z^i\_j\log(\hat{p}^i\_j)) \end{align} $$推定時は次の式をもちいる。 推定する\(\hat{y}^i\)は\(S\)の要素である。
$$ \hat{y}^i=\underset{j}{\operatorname{argmax}}(\text{dot}(v^i, \rho\_j)+\text{dot}(b,\rho\_j)); \rho\_j \in S\_{x^i} $$- 論文をこちらからダウンロードできます。