Zookeeper: Wait-free coordination for Internet-scale systems (2010)
February 12, 2023ZooKeeperは、リーダ選出と構成管理の機能を提供するためのインメモリーデータベースである。 データーベースは、ファイルシステムのような階層構造のwait-freeな抽象データ型であり、各ノードにはデフォルトで最大1MBの少量のデータを保存できる。 たとえば、ノードに設定を保存して共有することも、設定ファイルが編集中でないことを示すフラグ代わりのファイルを置くこともできる。
分散システムのための低容量のストレージサービスには、ZooKeeperのほかにもChubbyがある。 Chubbyが、処理性能よりも高可用性と信頼性を重視し、厳格な同期を保証する一方で、ZooKeeperは処理性能を重視する。 ファイルの変更をクライアントに通知するイベント駆動なAPIがあり、クラインアントはブロックを待機しなくてよい。 また、線形化可能性にかえて、Asynchronous-linearizability(A-linearizability)を保証する。 本来の線形化可能性を満たすためには、クライアントが外から観測できる操作を同時に2つ以上実行してはならない。 A-linearilzabilityは、制限を緩めて、複数の同時操作を認める。 ただし、この場合、同じクライアントが実行した操作の順序は未定義になる。 制限を守るときは、同じクライアントから送られたリクエストは送信順に処理される。
ZooKeeperは大きく分けてRequest Processor, Atomic Broadcast, Replicated Databaseからなる。
以下の図は、ZooKeeper内における読み込みと書き込みのリクエストの処理の流れである。
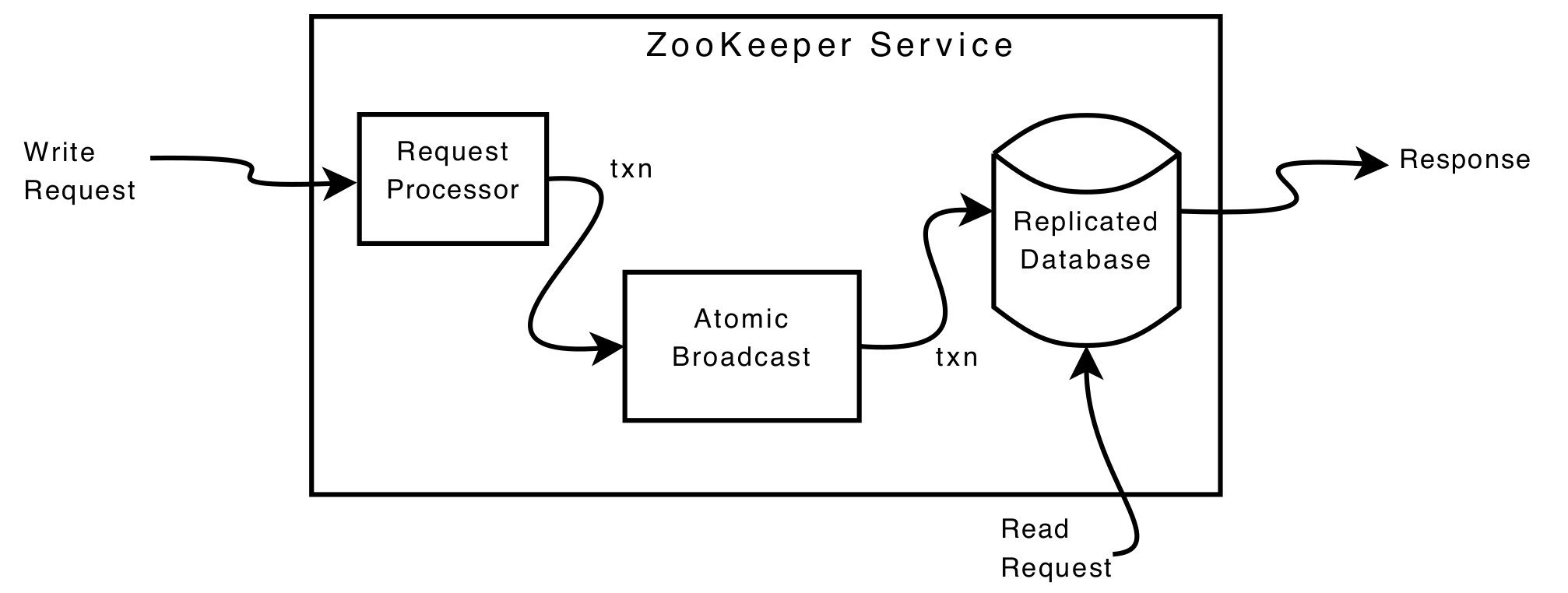 ZooKeeperのサーバーは、リーダー選出アルゴリズムZabで選ばれるleaderとそれ以外のfollowerに分かれる。
ZooKeeperのサーバーは、リーダー選出アルゴリズムZabで選ばれるleaderとそれ以外のfollowerに分かれる。
書き込みリクエストはleaderに送られ、読み込みリクエストはfollowerに送られる。
更新のAPIのシグネチャには、更新したいデータの位置や更新後のデータに加えて、更新対象のバージョンのパラメータもある。
たとえば、delete(path, version), setData(path, data, version)である。
Leaderは、引数のバージョンが最新のバージョンと一致する場合に限り、リクエストを受理する。
リクエストを羃等なトランザクションに変更し、トランザクションを適用する。
Zabは、リーダー選出だけでなく、メッセージを送られた順番にブロードキャストする機能がある。 また、新しく選ばれたリーダーのところには、リーダがブロードキャストを始める前に、以前のリーダーが送信したメッセージが届いていることが保証される。 このブロードキャストのプロトコルによって、follower同士のレプリケーションデータベースの状態を統一することで、followerが読み込みリクエストを処理できるようになっている。
論文のリンク
図は論文から引用されています。
雑記
更新系のAPIは、versionがあるので、compare and swapと同等の役割をはたし、wait-freeな抽象データ型の実装に使えるのだろうか。